宣伝と御礼と余談、および「わたしたちのインターネッツ・ドリーム」について
ご無沙汰しており大変申し訳ありません。林岳彦です。マイナンバーカードのことを「ナンバカ」って略すアラフィフです。
今回は、わたくしの書籍出版のご報告です。
来る2/28に、岩波書店から『はじめての統計的因果推論』という本を出版することになりました。
お気軽に読める本を書きたいと思って書いたので、お気軽に読んでいただければ本望です。みなさまどうぞよろしくお願いいたします。

この本を執筆できたのはひとえにブクマカーの皆様の後押しのおかげです。
私が因果推論について初めて本格的に書いたのは13年前の以下の記事で、この記事にけっこうブクマがついたことが当時の私にとってかなりの励みになりました。
takehiko-i-hayashi.hatenablog.com
さらに因果推論について書いた11年前の以下の記事はかなりバズり、多数の方々にブクマで褒めてもらったことにすっかり味をしめ、その流れに流されるまま今まで勉強と研究を重ねて遂に上掲書を世に出すことに繋がりました。
takehiko-i-hayashi.hatenablog.com
つまり、上掲書の出版の経緯の元をたどると、大きなきっかけは上記のエントリーに対して多くの見知らぬブクマカーが私の背中を押してくれたことでした。
思い返せば、当時のはてなダイアリーで同時期に書いていた優れた書き手の方々、とりわけwhat_a_dudeさんや蝉コロンさんといった方々からは、文章の書き手としてとても刺激を受けていました。また、往年の名執筆者であったコンビニ店長からは文章テクニックの多くを学ばせていただきました。私の文書力については、当時のはてなダイアリーの環境の中で研鑽されたところが大だと思います。上掲書の出版にあたり、そうしたはてな村の(元)住民の方々にも重ねて感謝申し上げます。(みなさま、今でもどこかで文章を書いておられますでしょうか)
今さらではありますが、はてなブクマカー諸賢には「まだ何者でもない人/もの/トピック」の背中によくわからん推進力を与えてくれるという魔法の力があるんだぜ!ということをここで感謝とともに声を大にしてお伝えしたいところです。浪越徳治郎先生の言うとおり、まさに「ブクマの心は母心、推せば生命の泉湧く」であります。
ブクマカーのみんな、まじで感謝してるよ!ありがとね!
余談
ここからは余談です。
私がまだ研究者として駆け出しだった20年ほど前の話ですが、そのほとばしる才能の煌めきに本当に好きになった、同じく当時駆け出しの漫画家の方がいました。「この才能を埋もれさせるわけにはいかない!!」と勝手に使命感に駆られた私は、単行本が出たら真っ先にAmazonレビューを書いて応援したり、mixiでコミュニティの管理人をしたり、時にはファンメールを出したりするなど今でいうところの「推し活」をしていました。それからかれこれ20年、その漫画家の方はやや紆余曲折はありつつも順調にキャリアを重ね、今やすっかり「時代を代表する漫画家」のお一人になられました(良かった)。その漫画家の方が順調にキャリアを重ねる一方で、私のこの20年は公私ともにかなりどん底の時期もありましたが、なんのかんので辛くもここまでなんとか生き延びてきました。このたび8年がかりで執筆した本書が遂に世に出ることになり、もうすっかり売れっ子となったその漫画家の方にダメ元で表紙絵をオファーしてみました。「あのとき推していた背中」が、いま振り向いてくれるなんて。そんな夢みたいな話がね、あるわけないじゃないですか、普通。
https://www.amazon.co.jp/gp/customer-reviews/R1A4UIPS8LXJ1P/ref=cm_cr_arp_d_rvw_ttl?ie=UTF8&ASIN=4088653238www.amazon.co.jp
【Zoomリンク追加】研究集会『エビデンスは棍棒ではない3』開催します!!(2/20@オンライン)
【2023/1/23にZoom登録のリンクを追加しました!】
みなさまお元気でしょうか? 林岳彦です。わたしは先月末の日曜の昼下がりに子どもと公園でサッカーの練習をしていた折に、調子に乗って*1三笘選手のステップの真似をしたところ足首を酷く捻ってしまい骨折中です。みなさまも三笘選手の真似をするときはくれぐれもご注意ください。
さて。
今回は以下の研究集会の告知(速報版)です。2020年に予定していた「エビデンスは棍棒ではない2」は残念ながらコロナ禍で中止になったままお蔵入りとなりましたが、エイヤと仕切り直してこの度の「3」の開催となりました。今回は「エビデンスとナラティブ」を巡る会となります。
=====================
エビデンスは棍棒ではない3:「エビデンスと社会とわたし」とその”隙間”を考える
企画者:林岳彦(国立環境研究所)、加納寛之(JST)、岸本充生(大阪大学)
開催時期:2/20(月)13:30-16:30@zoom
参加費無料でどなたでも参加できます。以下のリンクから、zoomウェビナーの参加登録をお願いします。
https://us02web.zoom.us/webinar/register/WN_TYg3v92rRYiciCHBB93k8Q
研究集会の趣旨:
統計的推測に基づく”エビデンス”は、ある種の法則性の存在を前提としている。また、われわれの社会とその制度も何らかの法則性の存在を前提に構築されている。しかし、その中に生きている「わたし」たちは、そうした法則性のみで説明できる世界の中ですんなりと生きているわけではない。わたしたちは、時には法則性の物語からはみ出し、時には法則性の物語に寄りかかりつつ、日々の生活を送っている。
しばしば、医療社会学などの分野では「科学的エビデンスの重視(あるいは標準医学の物差しに基づく”医療化”)」は、わたしたちの固有の生の在り方を軽視し排除するものとして批判されてきた。実際に、「エビデンスの不在」が「問題そのものの不在」として社会や制度の中で認識されることにより、個人の抱えるリアルな問題があたかも存在しないものとみなされてしまう状況がしばしば生じている。また、”科学的エビデンス”を巡る社会的コンセンサスが、個人の抱えるリアルな問題意識を不当な形で社会的・制度的に「上書き」してしまっている状況もある。
しかしその一方で、”科学的エビデンス”の獲得は、個人が直面した問題の「社会化」への重要な契機を与える一面も併せもつ。その意味で「アンチ・エビデンス」の立場は、「個人が抱えるリアルな問題の適切な社会化」への契機を失わせてしまう危険性をもつ。標準的エビデンスに対する拒絶(あるいはエビデンス至上主義者からの”斥力”)が、少なからぬ人々を”オルタナティブ・エビデンス”に基づく陰謀論やリスクの高い医療的実践へと至らせ、社会的分断や孤立化の原因となってきたことも、コロナ禍において私たちがしばしば目にしてきたことである。
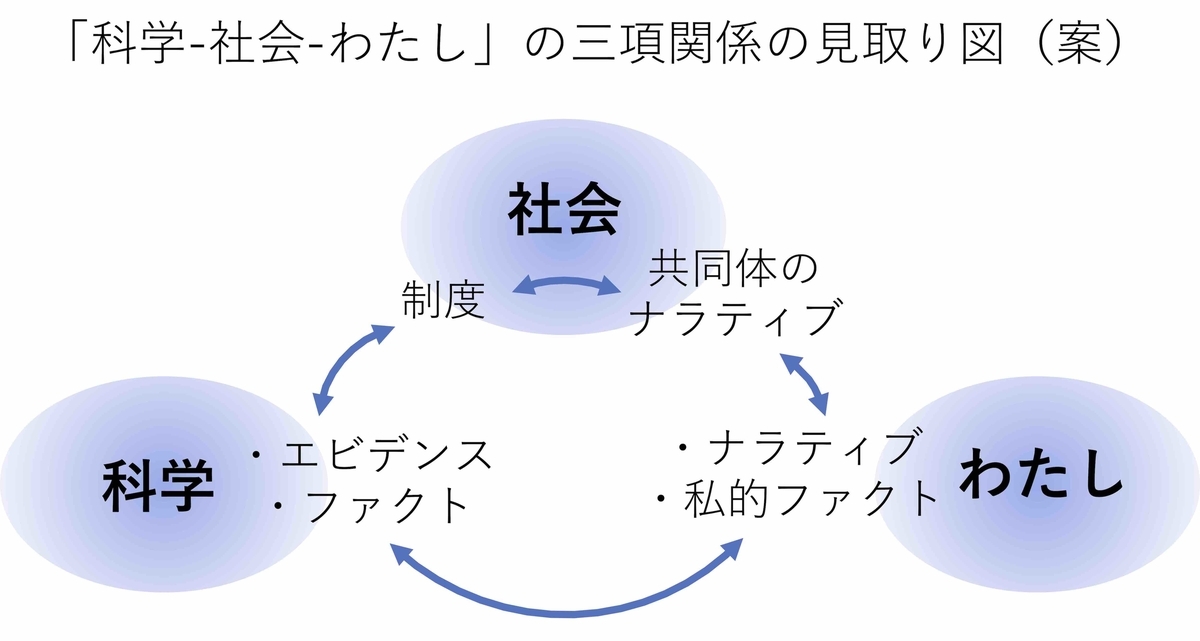
本研究集会では、そうした「エビデンス-社会-わたし」における複雑な三項関係(以下図)を念頭に、科学的エビデンスと「わたし」のありうべき位置づけについて議論する。今回の研究集会を通じて、「エビデンスと社会とわたし」とその”隙間”の存在について、そしてその”隙間”で身動きが取れなくなった人々に対する専門家や社会の「説明責任と応答責任」のありうべき姿についての認識と議論を深めたい。
講演者:
野島那津子さん(石巻専修大学)
『診断の社会学:「論争中の病」を患うということ(仮)』
竹林由武さん(福島医科大学)
『臨床心理学におけるエビデンスとケアと社会のあいだ(仮)』
安東量子さん(福島のエートス/NPO福島ダイアログ)
『個人線量の政策への利用について:数字の向こうに人がいる』
奈良由美子さん(放送大学)
『コロナ禍におけるリスクコミュニケーションと生活者の視点(仮)』
コメンテーター:
江守正多さん(国立環境研究所)
近藤雄生さん(ライター;代表作に『吃音 伝えられないもどかしさ(新潮社)』など)
佐野亘さん(京都大学)
#尚、「エビデンスは棍棒ではない」研究集会の1回目、2回目(2回目はコロナ禍で結局中止になりました)の情報は以下です:
https://takehiko-i-hayashi.hatenablog.com/entry/2019/02/21/130150
https://takehiko-i-hayashi.hatenablog.com/entry/2020/01/23/095302
関連書籍等:







")
")
")
")
")

")
")
*1:川崎サポなのでW杯での川崎出身者の活躍ぶりについつい浮かれすぎてしまいました
2021年、ささやかだけど、買って良かったもののメモ
こんにちは。今回は、おせち作りの待ち時間の間に、年末っぽく今年買って良かったもののメモを書いてみました。
そんなにゴツいものは買っていません。ささやかなものです。
(1) 常陸野ネストノンエール(私的ノンアル大賞2021)

今年一番の出会いは、この常陸野ネストのノンアルコールビールかなと思います。
コロナ期間中に店頭で出会う限りの色々なノンアル系飲料を試した中で、私としてはこの常陸野ネストのノンアルが図抜けて好きでした。
クラフトビール感が強く、なかなか美味しいです。ちゃんと醸されたものを飲んでるかんじがします。(なかなか店頭で出会うことがないかもですが、私はつくばのカスミ@LALAガーデンで出会いました)
*Amazonだと賞味期限の近いものが届くこともあるみたいなので、通販なら公式から買うのが安全かもです
kodawari.cc
(2) Unihertz jelly 2(3インチスマホ)

老眼が進んだこともあり、私はここ数年はネット記事・動画・電子書籍の閲覧には、iPhoneではなくiPad mini(旧型のほう)を主力として使っています。
iPad miniを日々の主力として使っていると、iPhoneを持っていても携帯電話以外の機能はほとんど被っているので、わざわざiPhoneも併用するのもなんだかなあと思い、この小さなアンドロイド端末に乗り換えました。
使ってみた感想としては、小さくて使いずらさを感じることもままありますが、電話とFelica用の端末と割り切って使う分には、ポケットの中で存在感なく収まるサイズ感もあり、なかなか気に入っています。
尚、使っているうちに最初の付属品のカバーが黄ばんできたので、このカバーに変えたのですが、このカバーに変えると見た目の雰囲気は一段階良くなるかんじです。
*Youtubeで見つけたレビュー動画も貼っておきます
www.youtube.com
(3) モンベルの小さい財布(カジュアルな小さい財布)
![[モンベル] mont-bell トレールワレット BK(ブラック)1133248](https://m.media-amazon.com/images/I/518fCBPUClL._SL500_.jpg "[モンベル] mont-bell トレールワレット BK(ブラック)1133248")
上記のJelly2をお財布ケータイとして使用することで物理カードの多くが不要になったのと、ちょうど以前から使っていた財布が傷んできたこともあり、財布をミニマル系の小さいものに変えようと思いました。
abrAsusの小さい財布もいいなと思ったのですが、生態学者としての初心忘るべからず*1と思い直し、モンベルの小さい財布にしてみました。安いし。
使ってみた感想としては、カード3-4枚、硬貨10枚程度内での運用が前提になりますが、ミニマリスト系の「小さい財布」としてはサイズ感・重量・機能のどれをとってもかなり良いかんじだなと思って気に入っています。
ただし一つだけ大きな欠点があって、上記のAmazonレビューでも言及がありますが、財布の綴じ具がないので、購入時のまま使うと折れ部が弱く、先がパカパカと開いてしまうところが困ってしまうところです。林は(Amazonレビューの人と同様に)両面テープでベルクロを付けて先がパカパカと開かないように加工して使っています。このちょっとの細工で使い勝手がかなり変わるかなと思います。
*尚、Amazonだと定価以上で売っていることが多いので注意が必要。定価は1980円(以下公式通販)
webshop.montbell.jp
*サイズ感は以下の動画が分かりやすいかなと思います。
www.youtube.com
(4) Bellroy Classic Backpack (iPad miniが取り出しやすいバックパック)
 - Black")
「シンプルで、iPad miniの出し入れがしやすいバックパック」を探していて、このバックを買いました。この前面のファスナーの部分のポケットがちょうどiPad miniを出し入れするのにちょうど良いサイズ感で、気に入っています。
このバックも一つだけ大きな欠点(個体差かも?)があって、肩ストラップのサイズ調整のひもが直ぐ緩みがちなのにやや困っています。林はそのストラップ部分をベルクロで巻いて緩まないように固定して使っています。ここが固定されるとかなり幸せです。
*デザインや機能については以下の動画から雰囲気は使めるかなと思います。
www.youtube.com
はい。というわけで、2021年のささやかだけど買ってよかったものメモでした。
ではみなさま良いお年を!
*1:生態学会のドレスコードど真ん中はモンベルなのです
重回帰分析が突然バグるケース:偏りの大きい変数での調整には注意!
こんにちは。林岳彦です。統計的因果推論の本の初稿を書き上げるまで髪の毛を切らないぞ、と願掛けしましたが、書けないままどんどん髪の毛だけが伸びてきています。いつか塔に籠もってラプンツェルになるかもしれません。あるいは突然全てが嫌になって前田大然になるかです。今日は久々のリアル外勤のスキマ時間でエイヤッとこの記事を書いています。
さて。
今日は、ややマニアックな話として、重回帰分析が突然バグる状況について書きたいと思います。結論から言うと、重要な特性において分布の偏りが大きい変数で調整するときに、調整によって回帰が突然バグる場合があるので注意しましょうという話です。
例を見ていこう
例として、ある環境汚染物質が健康被害を引き起こしている例を考えます。ここでは、それぞれの人の汚染物質への曝露量と、健康影響の程度(バイオマーカーの値で測定)のデータが得られているとします。
以下の話では、「環境曝露によって健康影響(バイオマーカーの値)の値が増加するという真の因果関係がある」という状況を考えていきます。ここで、曝露量とバイオマーカーの値の関係は、以下のシグモイド曲線で規定されているとします。(尚、毒性学的には曝露量と反応がシグモイド型になることはとても一般的な想定です)

具体的データとして、以下の散布図の例を考えていきます。このデータはRでシグモイド関数から生成した値に誤差を足して作成したものであり、ここで見られている相関そのものはシグモイド型の「曝露量→バイオマーカーの値」の用量反応関係を反映しています。ただし、誤差もまあまあ大きいため、全体をぱっと見すると線形の比例関係にも見えています。

このデータをRで線形単回帰(「バイオマーカー」が目的変数、「曝露量」が説明変数)をしてみると、以下のような解析結果になります:
## Call: ## glm(formula = BiomarkerScore ~ scale(ExposureDose), data = dataAB.df) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -13.4270 -2.7530 0.0925 3.5405 9.1241 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -4.5716 0.7639 -5.985 5.98e-07 *** ## scale(ExposureDose) 3.6659 0.7736 4.739 2.99e-05 ***
散布図から容易に予想されることですが、曝露量(ExposureDose)との強い関連が推定されています(偏回帰係数=3.6659, p<0.0001)*1。結果の解釈としては、「曝露量と健康影響には強い関連がある」という結論になります。元々シグモイド型のデータに線形回帰をしているので、予めモデルは誤設定されていることになりますが、概ね正しい結論とメッセージが得られていることになります。線形モデルでも実用上はまずまずの推定はできるよね、というかんじです。
さて次は、データの値そのものは全く変えずに、設定を少し変えてみます。今回のデータは、異なる2つの地域(A村とB村)から得られたデータを含んでいる状況になっています。散布図は以下になります:

今回のポイントとして、この例ではA村とB村で曝露量の分布は重なっていることを覚えておいていただければと思います。さて、ここで説明変数として「曝露量」と「地域」を考慮した線形重回帰分析をしてみると、結果は以下のようになります:
## glm(formula = BiomarkerScore ~ scale(ExposureDose) + Area, data = dataAB.df) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -13.1285 -2.7341 0.0121 3.3540 9.4185 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -4.2757 1.0931 -3.912 0.000378 *** ## scale(ExposureDose) 3.6783 0.7831 4.697 3.58e-05 *** ## AreaB -0.5918 1.5466 -0.383 0.704176
ここでは「曝露量(ExposureDose)」については前回の解析とほぼ同じような強い関連が推定されています(偏回帰係数:3.6783, p<0.0001)。一方、「地域(Area)」については特に関連がないと推定されました(偏回帰係数:-0.5918, p=0.701476)。全体的な結果の解釈は前回と同じで、「曝露量と健康影響には強い関連がある」という結論になります。穏当です。
さてここからが本番です。
データの値そのものは全く変えずに、設定をさらに変えます。今回は、異なる2つの地域(A村とB村)で曝露量の分布が全く重なっていない状況を考えます。たとえば、A村の中に汚染物質の特異的な発生源があるような状況ではこのようなパターンのデータになることが実際にありえます。散布図はこうです:

多重共線性も気になるので書いておきますが、この例では「地域(村)」と「曝露量」の相関係数は0.84くらいです。
ここで前回と全く同様に、説明変数として「曝露量」と「地域」を考慮した線形重回帰分析をしてみると、結果は以下のようになります:
## glm(formula = BiomarkerScore ~ scale(ExposureDose) + Area1, data = dataAB_mod1.df) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -8.519 -2.712 1.443 3.054 5.755 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -0.1971 1.1638 -0.169 0.866 ## scale(ExposureDose) -0.6486 1.1568 -0.561 0.578 ## Area1B -10.2929 2.3106 -4.455 7.5e-05 ***
はい!「曝露量(ExposureDose)」との関連は完全に消えてしまいました(偏回帰係数の符号は負に変化:-0.6489, p=0.578)。その代わりに、今回は「地域(Area1B)」との強い関連が推定されています(偏回帰係数:-10.2929 p<0.0001)。 念のため繰り返しますが、曝露量とバイオマーカーの値は前回までのデータと一切変わっていません。
この推定結果をそのまま解釈すると、「A村で起きている健康被害にはこの汚染物質の曝露は関係ないんだ!」「A村自体が問題なんだ、汚染物質とは別の原因があるんだ!」となります。これでいいはずがありません。このデータはたとえばA村内に特異的な発生源があるためにこうしたパターンになっているだけで、実際には健康被害は汚染物質の曝露で生じているわけです。この解析結果は、健康被害の原因を見つけるという観点からは、定量的にも定性的にも完全に間違った推定結果になっています。 こうした結果は、A村での環境汚染に対策における不作為を正当化しかねないような、かなり由々しき解析結果となってしまっています。
ついでとなりますが、設定を少し緩めて、部分的に分布が重なっている状況で全く同じように線形重回帰解析をした例は以下のようになります:

# glm(formula = BiomarkerScore ~ scale(ExposureDose) + Area2, data = dataAB_mod2.df) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -10.9165 -3.0670 0.7647 3.4124 9.8028 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -2.405 1.252 -1.921 0.0625 . ## scale(ExposureDose) 1.659 1.198 1.385 0.1744 ## Area2B -5.098 2.393 -2.131 0.0398 *
分布に完全に重なりがないときほどひどくはありませんが、あいかわらず「曝露量(ExposureDose)」との関連は不明瞭であり(偏回帰係数:1.659, p=0.1744)、「地域(Area2B)」には有意差がついている(偏回帰係数-5.098, p=0.0398)という、いまだミスリードを起こしうる、なんともぼんやりとした推定結果になってしまっています。
まとめとして上記の現象を一枚のポンチ絵にしてみると、以下のようになります:

なんでこんな推定結果になるの?
隙間時間の中でここまで書いてきて、かなりお腹が空いてきてしまい、説明するのがだんだんと面倒くさくなってきていますが(私よりうまく説明できそうな方はぜひtwitterなどでご解説いただければと思います)、要因を簡単にまとめると以下のようになります:
- 「非線形応答に線形モデルを当てはめている」かつ「異なるカテゴリー(A村とB村)で曝露量の分布の重なりがない(小さい)」
この両方の状況が同時に生じると、下図のように、「各カテゴリー内での線形フィットのトレンド」と「全体でみたときの関係のトレンド」の乖離が大きくなってしまうことにより、関連の大きさの推定を大きく狂わせるバグ的な状況が成立してしまうことがあるわけです。

これは単回帰では大きな問題が無かったのに、調整のために変数を加えたことでかえって問題が生じるという、けっこう回避難度の高いバグかなあと思います。こうした状況はレアケースであるとは思いますが、推定が量的・質的に完全に狂ってしまう場合もありえるため、誤りの帰結は重大になりうるところが怖いところです。
ここまで読んできて、「調整のための変数の追加により生じるバグ」であることから、いわゆる合流点バイアスを思い浮かべた方もいるかもしれません。しかし、上記の話は本質的にはモデルの誤設定が根本にある話であり、(いわゆる)合流点バイアスとは少し違う話*2で、たとえば、適切なモデル(何らかの制約を課したシグモイド型のモデルなど)で曝露量と反応の関係を回帰していれば、こうした調整によるバグは生じない可能性があります*3。
そもそもなんでこんなこと書こうと思ったの?
『欧州の排外主義とナショナリズム』という本を読んでいたら、その中で「収入の多寡は移民忌避的な態度の原因でない」という解析結果が示されていて、でももしかしたら下図のようなケースもありうるのかなあ?とちょこっと思ったからです。

本当にこういうケースが生じていると思っているわけではないですが、ちょっと思ってしまったついでにこの機会にテクニカルな記事として話をまとめてみたという次第です。
最後に伝えたいこと
解析ソフトにかける前に色々なパターンで散布図を描いて眺めてみてデータに病的な部分(事前に想定していなかった極端な偏りの傾向とか)がないかを確かめるという作業は、地味ですが、本当に本当に大事な作業なので、必ずやりましょう!
以上、いかがでしたでしょうか。(空腹のため書く気力がもう切れました*4)
ではまたどこかで
引用文献

講演資料アプ2件:「エビデンスの政策利用のための議論枠組みの提示」&「因果推論の諸理論の統合的理解」
すっかり冬ですね。おでんを作るときに、もっと汁に浸したいのに、はんぺんが汁から浮き出てこようとするのでイラッとすることはありませんか? こんにちは。林岳彦です。このブログではご無沙汰しており大変申し訳ありません。ずっと本を書いているのですが、完成する気配はありません。
さて。
12月の前半に2件ほど発表する機会をいただいたので、今回はその講演資料をアップします。
1件目は哲学オンラインセミナーで発表機会をいただいた、「科学的エビデンスの政策利用のための議論枠組みの提示」をテーマとした発表です。直近に公開された英語論文(Kano and Hayashi 2021)の内容の紹介が中心です。(当日の発表では時間が足りなくなって後半をかなり飛ばしてしまいました。大変申し訳ありませんでした)
2件目は応用数理学会ものづくり研究会で発表機会をいただいた、「因果推論の諸理論の統合的理解」をテーマとした発表です。Rubinの潜在反応モデルとPearlの構造的因果モデルの統合的理解がテーマです。(大きなテーマを60分枠に詰め込んだので、ややギチギチした作りになっています。大部分は過去の発表のマッシュアップですが、統合的理解のところの説明はちょっとアップデートされています)
ではみなさまも、浮いてくるはんぺんにイラッとしたり、ゲレンデがとけるほど恋したり、着てはもらえぬセーターを涙こらえて編んだりしながら、それぞれの冬ライフをお過ごしいただければと思います。お互いに体調に気をつけていきましょう!
関連文献

- 作者:セオドア・M・ポーター
- 発売日: 2013/09/21
- メディア: 単行本

")
- 作者:コリンズ,ハリー
- 発売日: 2017/04/24
- メディア: 単行本
")
- 作者:立石 裕二
- 発売日: 2011/04/02
- メディア: 単行本

- 作者:学, 黒木
- 発売日: 2017/08/24
- メディア: 単行本
")
統計的因果推論―回帰分析の新しい枠組み (シリーズ・予測と発見の科学)
- 作者:宮川 雅巳
- 発売日: 2004/04/01
- メディア: 単行本
")
- 作者:清水昌平
- 発売日: 2017/09/08
- メディア: Kindle版
")
調査観察データの統計科学―因果推論・選択バイアス・データ融合 (シリーズ確率と情報の科学)
- 作者:星野 崇宏
- 発売日: 2009/07/29
- メディア: 単行本
")
- 作者:岩崎 学
- 発売日: 2015/11/10
- メディア: 単行本(ソフトカバー)

- 発売日: 2016/06/10
- メディア: 単行本(ソフトカバー)
【!開催延期注意!】研究集会『エビデンスは棍棒ではない2』@東大本郷(期日未定)
こんにちは。林岳彦です。冬は寒いですね。言葉は三角、こたつは四角、ネコは丸くなる季節です。今回は研究集会の告知(速報版)です。まさかの続編の開催です。何卒よろしくお願いいたします!
国立環境研究所社会対話・協働推進オフィスの主催により、「エビデンス、リスク分析と公共政策の関係について、価値/規範の側面から議論する」ことを目的としたオープンな研究集会を3月5日(木)に以下の要領で開催いたします。ご興味のある方々のご参加を広くお待ちしております!
【*参加費・事前登録等の必要はありません。ご所属や専門分野を問わずどなたでもご参加を歓迎いたします。また、来場者が会場の定員125名を超えた場合には席が不足する可能性がありますが、予めその旨ご了承のほどよろしくお願いいたします】
研究集会『エビデンスは棍棒ではない2:エビデンス、ナラティブ/コンテクスト、規範的議論のベストミックスに向けて』
注意:新型コロナウイルスの広がりを受けて、開催が延期(期日未定)となりました
新型コロナウイルスが落ち着き次第、また改めての開催を予定しておりますので、その際にはまたよろしくお願いいたします!
2020年3月5日(木)13:30-16:45(*終了時間は早まる可能性があります)
於:東大本郷ダイワハウス石橋信夫記念ホール
https://www.u-tokyo.ac.jp/campusmap/cam01_14_04_j.html企画者:林岳彦(国立環境研)・加納寛之(大阪大)・岸本充生(大阪大)
企画趣旨
環境学やリスク学の研究者がその活動の中で価値・規範にかんする問題に直面したとき、それをどう学術-公共政策のアジェンダとして学術的に/制度的に取扱いうるのかは悩ましい問題である。また、もしそれらの研究者が生産するリスク評価や学術的エビデンスが価値・規範の問題とあまりに切り離されて取り扱われてしまうと、社会的な議論の深まりを逆に阻害する道具となりかねないという懸念もある。昨年度の第1回「エビデンスは棍棒ではない」研究集会に続く第2回目の開催となる本研究集会では、「エビデンス、ナラティブ/コンテクスト、規範的議論のベストミックスへ」をテーマに、エビデンスとその背後にある質的・社会的な論点との関係を中心に議論する。
内容概要(*以下、演題は全て現時点でのものであり今後変更の可能性があります)
趣旨説明:
林岳彦(国立環境研)『この悲しみをどうすりゃいいの ― 数値と客観性と公共政策と私』
講演:
(1) 岸本充生(大阪大・データビリティフロンティア機構)『どうしてみんな科学(だけ)で決まったふりをしたがるのか』
(2) 齊藤誠(名古屋大・経済学研究科)『科学的なエビデンスと政策的なコンテキスト:豊洲市場移転における意思決定過程を振り返って』
(3) 安東量子(福島のエートス/NPO福島ダイアログ)『個人線量の政策への利用について:質的な論点からの考察』
(4) 五十嵐泰正(筑波大・人文社会科学研究科)『社会学はやはり「役立たず」なのか:「伝わらない」ことが前提の社会で何をなすべきだったのか』
コメント:
田中幹人(早稲田大・政治学研究科)『科学的情報の共有と社会的受容:マス/ソーシャルメディアの分析から』
佐野亘(京都大・地球環境学堂)『公共政策学の観点から』
関連図書
安東量子 (2019) 海を撃つ――福島・広島・ベラルーシにて. みすず書房

- 作者:安東 量子
- 出版社/メーカー: みすず書房
- 発売日: 2019/02/09
- メディア: 単行本

- 作者:福島民報社
- 出版社/メーカー: 福島民報社
- 発売日: 2018
- メディア: 単行本(ソフトカバー)
")
原発事故と「食」 - 市場・コミュニケーション・差別 (中公新書)
- 作者:五十嵐 泰正
- 出版社/メーカー: 中央公論新社
- 発売日: 2018/02/21
- メディア: 新書

みんなで決めた「安心」のかたち――ポスト3.11の「地産地消」をさがした柏の一年
- 作者:五十嵐 泰正,「安全・安心の柏産柏消」円卓会議
- 出版社/メーカー: 亜紀書房
- 発売日: 2012/12/06
- メディア: 単行本(ソフトカバー)
")
〈危機の領域〉: 非ゼロリスク社会における責任と納得 (けいそうブックス)
- 作者:齊藤 誠
- 出版社/メーカー: 勁草書房
- 発売日: 2018/04/24
- メディア: 単行本

- 作者:齊藤 誠
- 出版社/メーカー: 日本評論社
- 発売日: 2015/10/14
- メディア: 単行本

")
今年こそ真人間になりたい — WIFIから逃れるために2019年に買ったもの
統計的因果推論の本の執筆をしているのですが、進んでいません。実は執筆依頼を引き受けたのはもうかれこれ3年前になるのですが、かなりの部分、進んでいません。
執筆が遅れている原因は、はっきりしています。それは世界中に張り巡らされたWIFIのせいです。
WIFIがあるとついついインターネッツをみてしまうのです。しかしインターネッツはからっぽの洞窟なのです。からっぽの洞窟の中で見つけた宝箱の中さえもからっぽなのです。いや、本当は、完全には、からっぽではない、のだけれど、いくら洞窟の中を探検をして戻ってきても肝心の原稿は全く進んでいないのです。インターネッツは罠なんです。孔明の。
WIFIは人生の伴侶ではない
ついに私はそう気づきました。気づいた上に念のために復唱しました。
私は本を書かねばならないのです。本を書くためにWIFIから逃れねばならないのです。
というわけで、わたくしは2019年にWIFIから逃れるために幾つかの買い物をしたので、その買い物の次第をここにメモっておきます。
(1) 省機能携帯電話として:Nichephone-s 4G
")
現代社会においてWIFIとインターネッツから逃げるためにはまずスマホから逃げる必要があります。とはいえ携帯電話がないといざというときに連絡がとれなくて困ります。そこで、スマホは子供にお下がりとしてあげて、自分はNichephone-s 4Gというシンプルなガラケーに買い替えました。
良かったところ:
- 小さい
- かなり小さいので財布によっては定期入れのところに収納できる*1。これで2つ(財布+携帯)の荷物が一つにまとまったのは快適
- ひとつ前の世代のものより全体的に質が向上した*2
- いちおうSMSには対応している
- Googleアカウントなどでの二段階認証での認証番号を受信できるのはよかった*3
今ひとつなところ:
- 操作性はいまひとつ
- 基本的には操作はしづらい。携帯電話を使用する頻度が高い人にはあまりおすすめできない
- 端子が特殊
- 端子が特殊なので付属の端子プラグを持ち歩かないと出先で充電が切れるとかなり困る
(2) 省機能文章書きデバイスとして:ポメラ DM200

- メディア: オフィス用品
良かったところ:
- WIFIでインターネッツが見れないので執筆に集中できる(さいきんは執筆はほとんどポメラ@喫茶店でしている)
- 実は長らくあまり使い方がハマらなかったのだけれど、パラグラフモードでmarkdownで執筆するとわりと快適に書けるようになった
- これはパソコン側のmarkdownエディタをTyporaに移行したことで、数式を含むmarkdownテキストのポメラ→PCへの取り回しについて一定の段取りがついたことも大きな要素としてある
今ひとつなところ:
- 無線でのテキスト同期は色々とうまくいかず、結局SDカードでパソコンとデータをやりとりしており色々めんどい
- 現在の執筆フロー(色々めんどい):ポメラでmarkdown形式で執筆→SDカードでMac/Winに→Typoraで編集・PDF書き出し・印刷→紙で内容の検討→紙をみながらポメラでmarkdown形式で再執筆→(もどる)
(3) iPhoneの代替として:iPad mini
")
iPad mini Wi-Fi 64GB - シルバー (最新モデル)
- 発売日: 2019/03/28
- メディア: Personal Computers
良かったところ:
- インターネッツから逃げたいときにはNichephone-sとポメラだけもって出かければよいし、ネットが必要な場合だけiPad miniを持っていくという運用が可能になった
- iPhoneより大きいので老眼気味の眼にはとても優しい
今ひとつなところ:
- とくにない
- たまにiPhoneでないとできないことがある(Apple Watchとの連携など)
(4) 自宅ロシア化計画として:WiFiスマートプラグ

TP-Link WiFiスマートプラグ 2個セット 遠隔操作 Echo シリーズ / Googleホーム / LINE Clova 対応 音声コントロール ハブ不要 3年保証 HS105P2
- 発売日: 2018/08/09
- メディア: Personal Computers
自宅のインターネッツも必要に応じて元から遮断できればと思い、WIFIルータにスマートプラグをつけて時間制限でのオンオフ設定もしてました。これも一定の効果はありましたが、携帯があると4Gで結局インターネッツを見てしまえるのと、夜に友達とフォートナイトしたいという子供からの切なる要望があり今は使っていません。(逆に子供のWIFI利用を制限したい場合にはなかなか効果的であると思う)
今年こそ真人間になりたい
というか、そもそも意志を強くもつことによりインターネッツを見るのを我慢して執筆すればよいだけではないかというご意見もあるかもしれません。私もそう思います。
今年こそそんなグリットに溢れた真人間になりたいです。
そんな真人間に少しでも近づくために、今年は元旦から般若パイセンの筋トレアルバムを無限リピートしています:
(特典なし)")
- アーティスト:般若
- 出版社/メーカー: ポニーキャニオン
- 発売日: 2018/12/19
- メディア: CD
般若パイセンに鼓舞されていたら、今年こそ真人間になれるような気がしてきました。
今年こそは真人間になりたいです。それか中一から人生をやり直したいです。
そんな2020年の始まりですが、本年も何卒よろしくお願いいたします。
*1:因果関係は不明であるが、この電話を財布に入れていたところクレジットカードが不調になって交換したことがある。もしかしたら携帯電話の裏側のマグネットのせいかもしれないと思い、今は一応財布の中の携帯の裏側の位置にホームセンターで買った小さく薄い鉄板を入れて磁気の影響に対処している(が有効なのかはよくわからない)
*2:子供用の専用機として一つ前の世代のNichephone-s購入したことがあったのだけれど、こちらは何かと使いづらかったので結局あまり使われないままある日間違って洗濯してしまい壊れてしまった。現世代のNichephone-s 4Gではかなり使い勝手は改善した
*3:ただ操作性の問題でSMSを書く気にはとてもならない。